
The considerations below result from some recent projects at Sopra Steria.
The goal: having built a Data Lake, we want to deliver (ingest) in the Raw Zone the data from various sources,including several instances of an Oracle Database. We want to constantly have the most up-to-date version of the data present in the Data Lake ingest zone. In other words, we would like to achieve 1-way (active-passive) synchronization of the source database. The diagram below shows our data lake, and the orange components indicate the process we will discuss below.
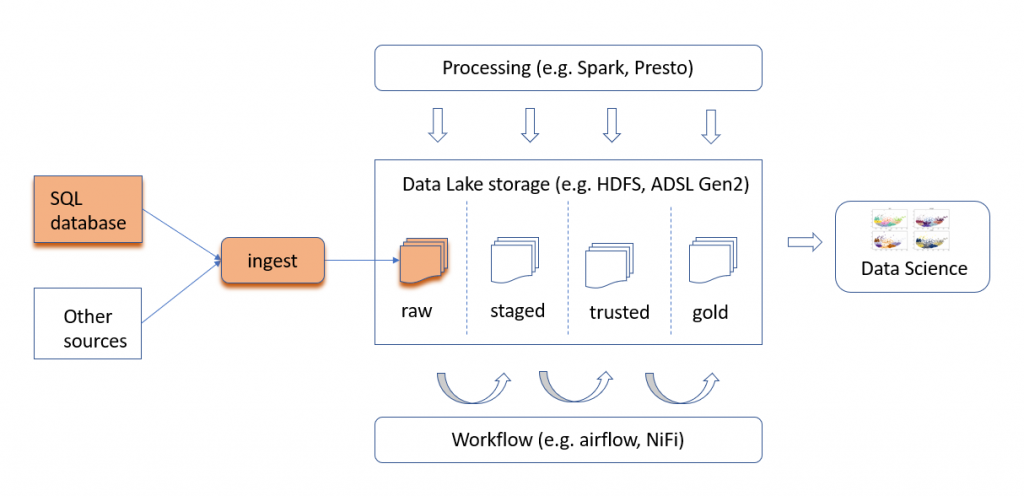
Why is this needed? Because the original source SQL database is a production system. We don’t want analytical queries impact it. This is why we need the fresh copy of the data in the Lake. (So, we are having a classic Data Warehouse business case, only that we need the data organized as the Lake.)
Why is this a problem? An old technique for achieving this is called CDC (Change Data Capture). The original idea for the CDC is to capture the delta of the source data (for instance, looking at the transactions from the redo log of the source database) and apply the same sequence of transactions (inserts, updates and deletes) in the destination database. So it works between two databases. But several problems arise when the destination system is not relational, ACID transactions-based database. For instance, HDFS commonly used as the datalake filesystem, is not designed for file updates. It is an append-only solution. So, in short: while INSERTS are easy to replicate, UPDATES and DELETES are not that easy.
There’s more technical issues too, making the design process difficult. Below follows a list of considerations, and some solutions.
The raw (entry) zone data format
- it is best to first decide on the desired sink data format (and data model)
- for us, the sink is the Raw Zone (which is where the data enters the Lake. Here to read more on Zones)
- there is good literature on the igest zone organization and formats possible
- still, setting this in stone at the beginning of the project sounds like the worst idea ever
- rule: decide as late as possible (from Lean)
- conclusion: unless you know exactly what you are doing, you want to deter this decision to allow for many formats. For instance: csv deltas, mongo, and Hive
The ingest technology
- think of this as ETL
- Sqoop, Flume and NiFi are examples of commonly used tools
- for traditional ETL, the choice is plentiful: Talend, Pentaho
- or, if your Lake sits on Azure: Azure Data Factory
- … but my thoughts go towards Apache Kafka.
- At first, Kafka seems an overkill. However:
- updates, inserts and deletes are in fact events. Events are core abstraction in Kafka. The conceptual architecture fits very well
- Kafka allows to deliver to multiple destinations, just like we just said
- Kafka has transient storage of data, so additional destinations can be added as topic consumers even after the reading started
- with multitude of connectors available, it sounds like good choice for an architecture that can evolve, for instance as shown below.
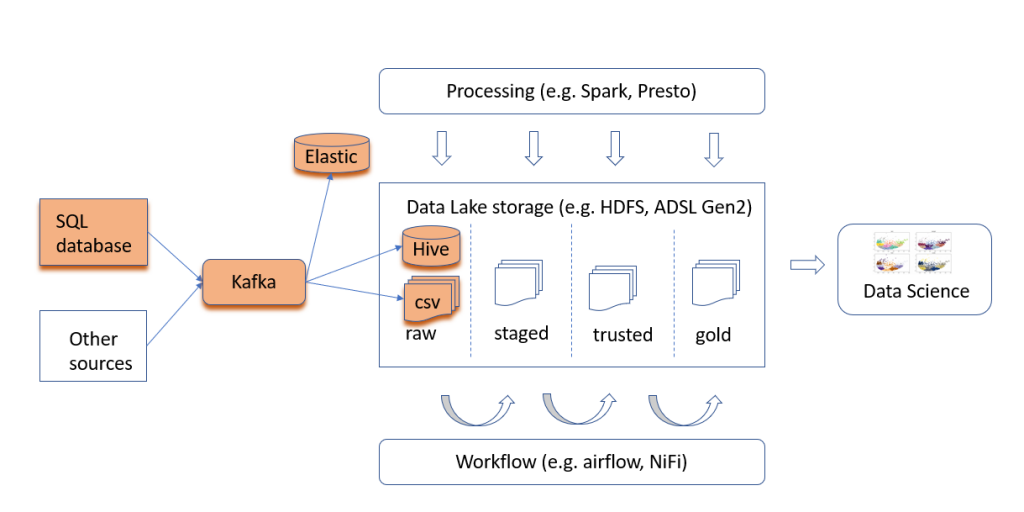
Connecting Kafka to the source, in CDC manner
- How to use Kafka for Change Data Capture, reading from a RDBMS?
- his Confluent post describes it well. Here is the summary:
- The simplest way is the Kafka JDBC connector
- but it comes with a price
- JDBC connector runs a SELECT on source each time, to find about the delta in data
- this is a hack really. It is not a CDC design.
- It hampers performance of the source system (possibly production)
- It also misses DELETES, because “how do you query for records that do not exist”?
- Debezium is better. It is a CDC solution. The price: complexity.
- Commercial alternatives: Attunity Replicate, Oracle Goldengate, Striim, and more.
Connecting Kafka to the destination, CDC manner
- Now we can come back to the destination (sink) bit. Again, what should it be?
- Commonly used Hadoop-family file formats: Avro, Parquet, ORC, but… oups!
- …Sitting on HDFS, they are great at appending data, but not modifying old rows. Not helpful with CDC.
- this alternative ingest data organization from SQL Chick blog inspired me to just store the deltas, in folders of separate, chronological csv files. Good, because then we only append data. Also, that’s what the Raw zone should be: data stored exactly as it came. This could be later reorganized into database, in the trusted zone
- but then we are reimplementing CDC. Do we have to do this?
- Here’s yet another solution: post-snapshot merging using Spark, Athena and Glue.
- And here’s Cloudera solution for incremental updates on Hive.
- They all look really complex. Isn’t there a simpler way?
- yes there is: Apache Hudi. It is a relatively new file format which, on top of HDFS, adds another view abstraction, providing for updating data and incremental view of the changes. Designed by Uber, now open source, it is a very clever design.
- Hudi allows for much more than we need, such as various views and preserving the update history in layered files. Here’s Hudi history from Uber. It looks that Uber created Hudi due to very similar challenge to ours
- Yet another alternative is to set up a regular SQL database as data sink, such as PostgreSQL at ingest zone (outside HDFS).
- No one said we have to use HDFS for everything 🙂
- Then the problem boils down to CDC between two databases, using Kafka. Not difficult.
- Those two solutions, quoted above (either Hudi over HDFS or an SQL RDBMS outside HDFS), seem the simplest way to achieve the goal
Below is the resulting architecture of the Data Lake Change Data Capture ingest process, with core implementation arranged as orange blocks.
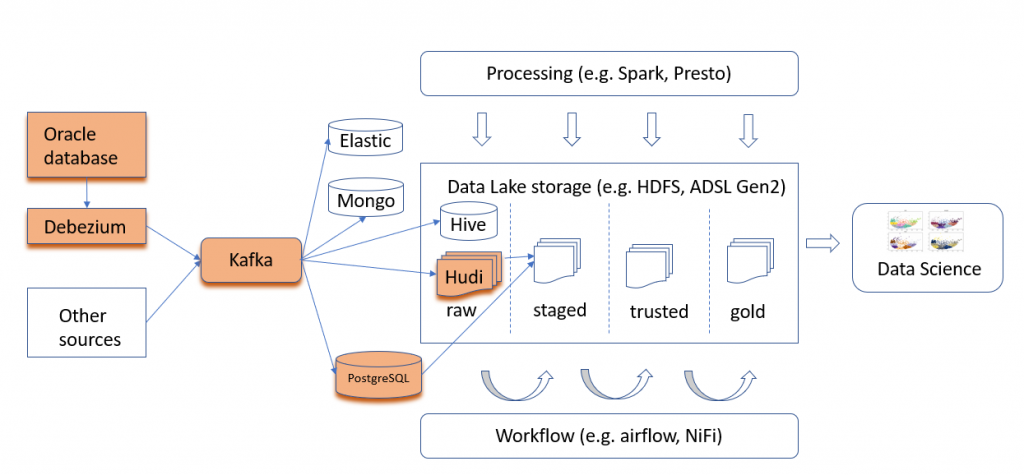
Nice one, I am very much impressed
Can we share more information and architecture