
In Lecture 6 of our Big Data in 30 hours class, we talk about Hadoop. The purpose of this memo is to summarize the terms and ideas presented.
About Hadoop
-
- Hadoop by Apache Software Foundation is a software used to run other software in parallel. It is a distributed batch processing system that comes together with a distributed filesystem. It scales well over commodity hardware and is fault-tolerant. Hence Hadoop’s popularity: it can manage a cluster of cheap computers and harness their CPU cycles so they work together like a supercomputer.
- It is easy to get confused among numerous brands in the Hadoop ecosystem. But if you just focus on the basics, it suddenly becomes quite easy. Most importantly, Hadoop’s two core packages are: MapReduce and HDFS.
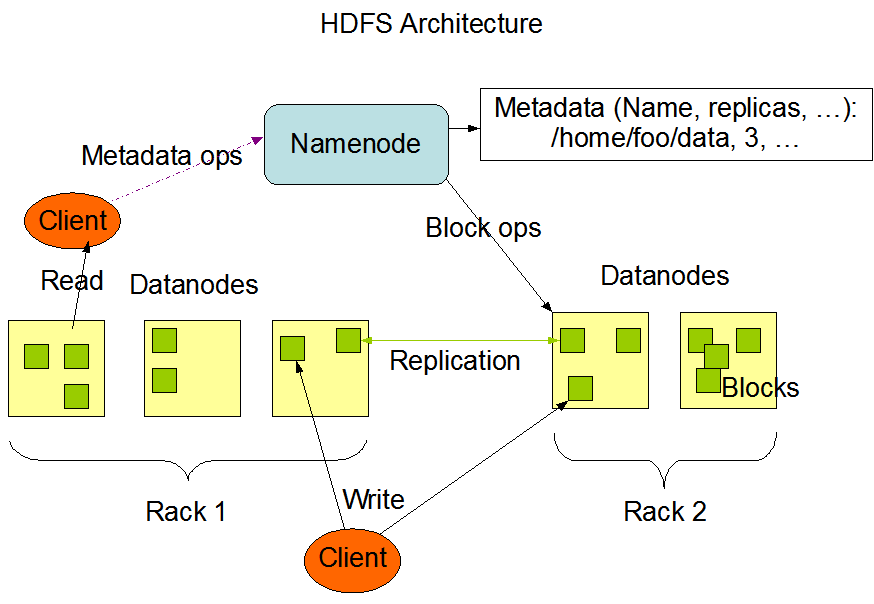
- HDFS is the distributed file system and it is widely used. The architecture follows a simple concept: every computer on your cluster runs a DataNode, with one central NameNode helping to orchestrate the NameNodes.
- MapReduce, later augmented with YARN, is a batch scheduling system to run parallel tasks processing data from HDFS. The architecture, again, is real simple: there is one central ResourceManager that manages NodeManagers (one per worker node). Note: these days, besides MapReduce, there are other ways to run data in Hadoop HDFS cluster, such as Hive, or Apache Spark.
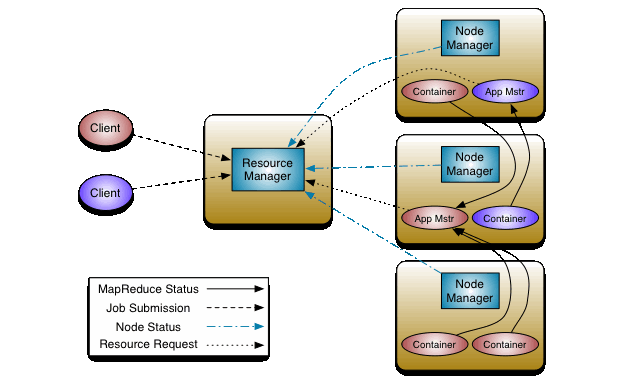
- The basic scenario? A client uploads data files to HDFS, and sends a job request to JobTracker. The JobTracker splits the job into tasks and schedules each to one of the TaskTrackers. TaskTrackers perform their part of the job and store the result back in HDFS. When the job completes, the client is notified that the result can be downloaded.
- Other important tools in the ecosystem which you may look at later: Yarn is a scheduler on top of MapReduce. Hive allows to query Hadoop in SQL-like fashion. Sqoop is like an ETL from RDBMS to HDFS. Pig is data workflow language. HBase is a NoSQL data store similar to BigTable. More tools here or here.
Setting up Hadoop
Hadoop can be set in one of the three modes: Local mode (all runs in one JVM), Pseudo-distributed mode (still running on one machine, but with all bells and whistles normally found in the installation) and Fully Distributed Mode (on a cluster). Use Fully Distributed if you have access to a compute cluster. Use Pseudo-distributed for learning in the absence of such a cluster.
To set up Hadoop in Pseudo-distributed mode on your laptop, use Docker. Then just pull a Hadoop image from Dockerhub. I tested this image with Hadoop 2.7.0 (credits to sequenceiq) it works well. Here is all you need to do:
docker pull sequenceiq/hadoop-docker docker run -it sequenceiq/hadoop-docker /etc/bootstrap.sh -bash
Otherwise, to install Hadoop 3 on one node manually, you may follow this instruction by Mark Litwintschik.
In our lab we have set up Fully Distributed Hadoop 3.1.1 install on 8 nodes.
hadoop@ubuntu:~$ hadoop version Hadoop 3.1.1
Manage the active services
On standalone node: bash-4.1# jps 655 NodeManager 218 DataNode 560 ResourceManager 128 NameNode 379 SecondaryNameNode 3383 Jps
Or simply:
bash-4.1# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 128 1.2 3.9 1574644 209084 ? Sl 07:40 0:27 /usr/java/default/bin/java -Dproc_namenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir root 218 1.1 2.7 1583688 144156 ? Sl 07:40 0:25 /usr/java/default/bin/java -Dproc_datanode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir root 379 0.8 3.1 1555144 168076 ? Sl 07:40 0:18 /usr/java/default/bin/java -Dproc_secondarynamenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoo root 560 2.3 4.1 1759560 222140 pts/0 Sl 07:40 0:52 /usr/java/default/bin/java -Dproc_resourcemanager -Xmx1000m -Dhadoop.log.dir=/usr/local/hadoop/logs - root 655 2.2 7.4 1624984 396724 ? Sl 07:40 0:49 /usr/java/default/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/usr/local/hadoop/logs -Dyar
if services are missing, (re)start them. Some commands are:
start-all.sh start-dfs.sh stop-dfs.sh start-yarn.sh bin/hadoop-daemon.sh start datanode
Run a sample MapReduce job
cd $HADOOP_PREFIX # run the mapreduce bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+' # check the output bin/hdfs dfs -cat output/*
Access online management tools
First, run your standalone install with following ports published:
docker run -it –publish 50070:50070 –publish 8088:8088 sequenceiq/hadoop-docker /etc/bootstrap.sh -bash
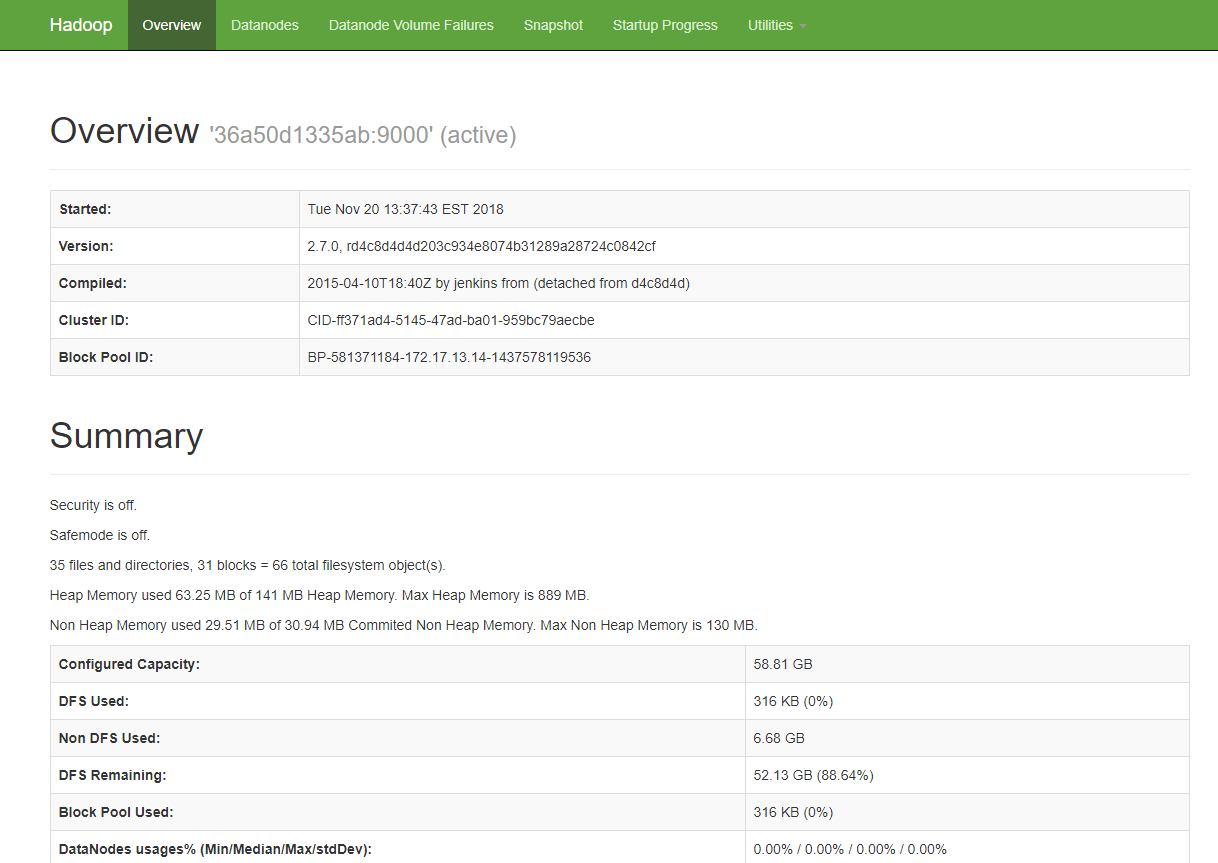
Access HDFS management console at localhost:50070
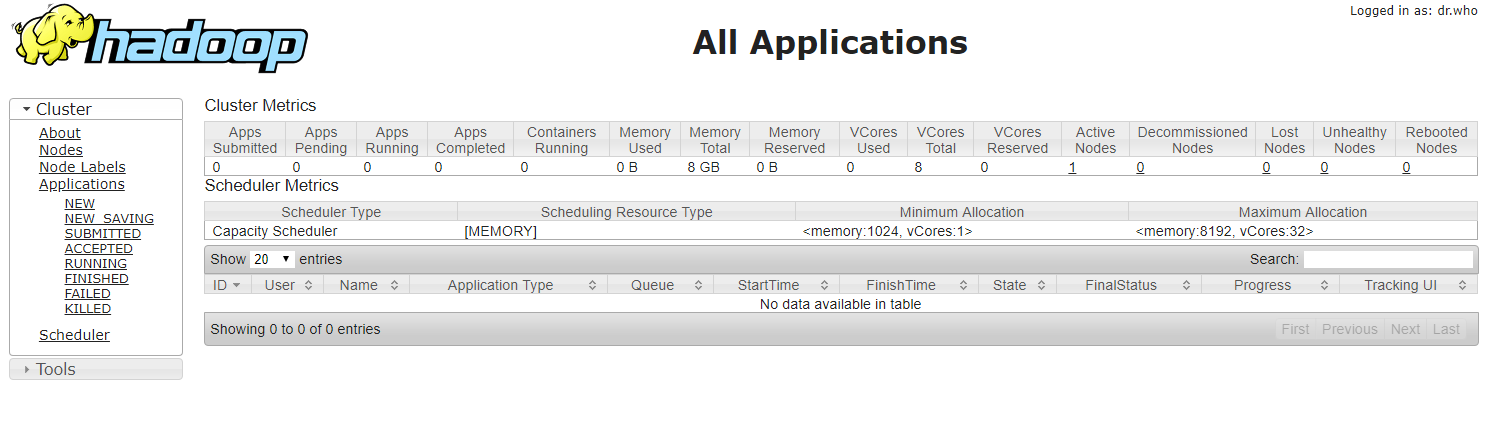
Access MapReduce management console at localhost:80088
Understand the cluster config
Here is defined where are worker nodes and who is the master node.
hadoop@ubuntu:~$ ls /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://149.156.146.140</value>
</property>
</configuration>
hadoop@ubuntu:~$ more /usr/local/hadoop/etc/hadoop/workers 149.156.146.141 149.156.146.142 149.156.146.143 149.156.146.144 149.156.146.145 149.156.146.146 149.156.146.147
It was so interesting to read, really you provide good information.
Your post is very great.I read this post. It’s very helpful. I will definitely go ahead and take advantage of this. You absolutely have wonderful stories. Cheers for sharing with us your blog.
Python training in Noida