
I have 130,000 help desk tickets with multi-lingual descriptions. I need to divide this set into categories, such as “password reset”, “license expired”, or “storage failure”. Why? Users could then allocate a category to a new ticket they create. Then any new ticket will be routed immediately to the right specialist and in the result it will be solved faster. Is there a way to automatically categorize the tickets into categories that do not exist yet?
We want to grop together those descriptions which are semantically similar. The approach I want to try is k-means clustering, based on phrase similarity. However, the fact that the task descriptions are multi-lingual pose a technical problem. The similarity algorithms are typically based on a known corpus, typically specific to a particular language. But I am having a mix of sentences in Norwegian, French, English, and machine generated output (which I should technically consider a separate language), all in one set. To address this issue (semantic similarity for mix of languages), I did post questions on stack overflow and in the PL Data Science Facebook group, and internally to my Sopra Steria colleagues. The replies were very inspiring (thank you all!) In the end I developed the following combination of methods, which works well and yet leaves plenty of space to improve.

The diagram above depicts the procedure. Below I will explain the steps and show the outcome.
Step 1: set up the corpus
We first need to create (or aquire) a corpus, because this is the base for any Natural Language Processing. The corpus is nothing else than collection of phrases in a given language, on which the models will be trained. My approach was driven by simplicity: I created a custom corpus based on all the ticket descriptions I had in my database. In the result, I created a hybrid “language” composed of combination of phrases in English, French, Norwegian and machine-generated. Its size, the number of words and number of unique words are:

The alternative approach would include: to download existing multilingual corpuses, or using a native corpus in English after translating stuff with TextBlob or the like.
Step 2: train the similarity model
We need the corpus to create (train) the model. The model is nothing else but a transformation of one data representation (words) into another data representation (vector of numbers, called word embeddings). The reason we need word embeddings is that this can lead us to discover word similarity.
To prepare the model for my word embeddings I trained the word2vec model from gensim library. The alternatives to gensim are: GloVe, BERT, or SpaCy.
Step 3: create word embeddings
Using the model, we want to convert all the words we have into word embeddings (vectors of numbers). Here is an example of three words mapped to a vector of 100 numbers, using the model.
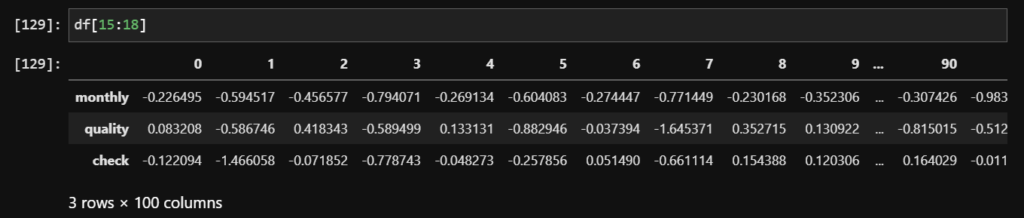
The reason to do this is to achieve ability to compute word similarity metrics. Let’s check:
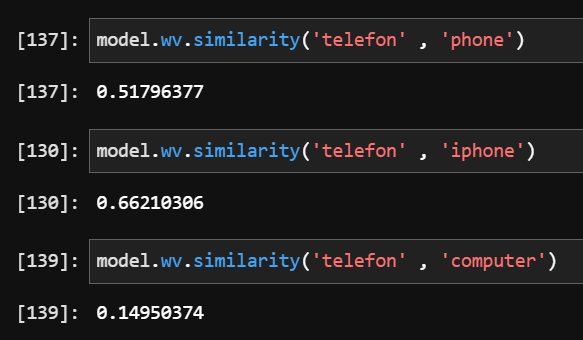
The results are promising: our model knows that the Norwegian word telefon is more similar to English iphone, than to computer. In the same time, this leaves space for improvement: the similarity metrics telefon-phone should be higher. But for a prototype, it is good.
step 4: create sentence embeddings
Knowing what words are semantically similar, we now need to understand which phrases are similar. For the prototypical solution, I adopted the direction from this thread. In essense, in a simplistic approach a sentence vector is defined as a combination of all the vectors of all the words in the sentence. I computed an average (rather than sum) of the vectors. This can be done manually, no specialized library is needed. In the result we achieve, again, the vectors (embeddings), this time representing sentences. Again, let us try the similarity of selected sentences, this time using the cosine from spatial package:
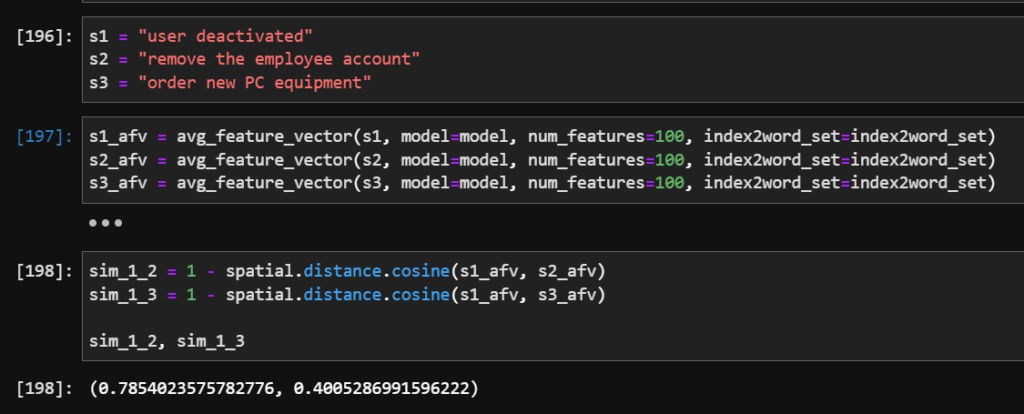
Again, the results are far from perfect, but promising. The phrases “user deactivated”, and “remove the employee account” were correctly ranked as similar (0.68), while the phrase “order new PC equipment” was ranked as semantically more distant (0.4). Makes sense.
Step 5: visualize with t-SNA
Let’s visualize the meaning space to see if we see some groups already. This step is not necessary, but it helps to comprehend what we are doing, especially at the prototype/research level. You cannot visualize the vectors directly, but you can reduce the dimensions with t-SNA to “flatten” the multidimensional vectors into a two-dimensional chart. Here is the result:
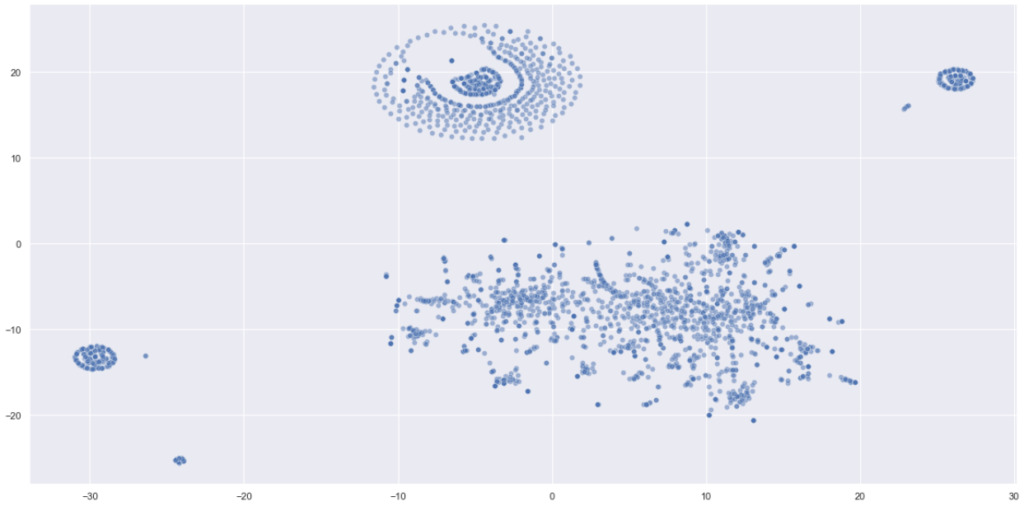
In the chart above, one dot is one ticket description (sentence). Seeing these interim results, we can be cautiously optimistic. We have been looking for semantic groups of tickets, and we found some. The visualization seems to follow the pareto principle: large part data of will be part of a handful of top categories, while the remaining data will form a “long tail”, split between numerous categories. It seems this is exactly what we are seeing above: three large blobs and the rest.
step 6: clustering
The last step is clustering. I used KMeans algorithm with various parameter combinations to identify the groups of phrases that sit close to each other in the multidimensional meaning space (which indicates that they may be similar). The visualization of this step shows that the separate groups were correctly identified as independent clusters (represented by a different color). With higher number of clusters (bottom right) the visualization is less apparent.

The result
At this point it is worth checking the results. What are the groups of phrases that were classified as similar? Below an example of clustering into 30 groups. The group 23, anonymized, looks like this:
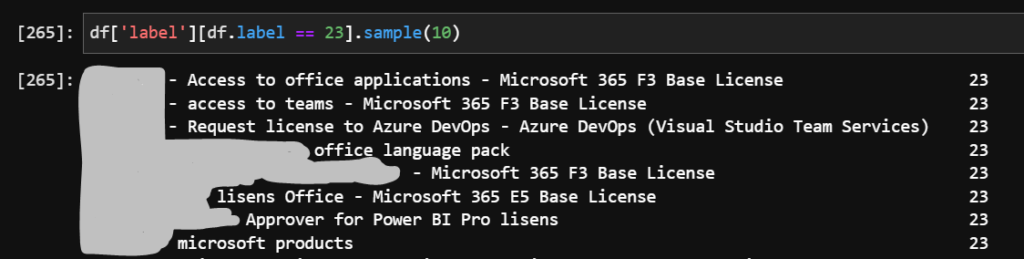
It is quite interesting: the requests for Microsoft products were classified as similar, regardless of the language. What is more interesting, even though the word “Power BI Pro” does not mention the word Microsoft, it was classified as related.
This completes the exercise. We have still much to learn and each of the steps could be improved. That said, the results are already good enough for practical purpose, as the example above shows: aparently among the 130,000 tickets there seem to be quite a bunch of Microsoft license requests (some in English, some in French and some in Norwegian). Thus it makes sense to create a separate category for those tickets, which in the near future could be routed directly to a Microsoft license manager. Achieving similar categorization with manual review of 130,000 tickets is of course possible, but more cumbersome and more error-prone.
Credits: as usual, the credits go to Sopra Steria and my data analytics team, where this research was done. Yes we are hiring 😉