

Much of the public discourse in Data Science focuses on model optimization (selection of regressors/classifiers, hyperparameter tuning, model training and improvment of the prediction accuracy). Less material is available on using and deploying these trained Machine Learning models in production. I was asked to summarize my experience in this domain in a series of workshops, one of which I deliver next week at the TopHPC conference. Here is a summary.
The best way to understand a production Machine Learning pipeline is to build one, which is what we are doing at the workshops.
For a scenario, imagine a system to classify the incoming scanned documents. Our company mailbox receives several types of documents: an invoice, an offer, a purchase order, a job application, a complaint, a service request, and other. Any minute, a new document might land in the ingest. The system is expected to classify the incoming document and send it to the right department for further processing.
To build such a system, we effectively need two pipelines: one for the training phase, the other for the production phase.
Here is the traning phase pipeline. It works like this:
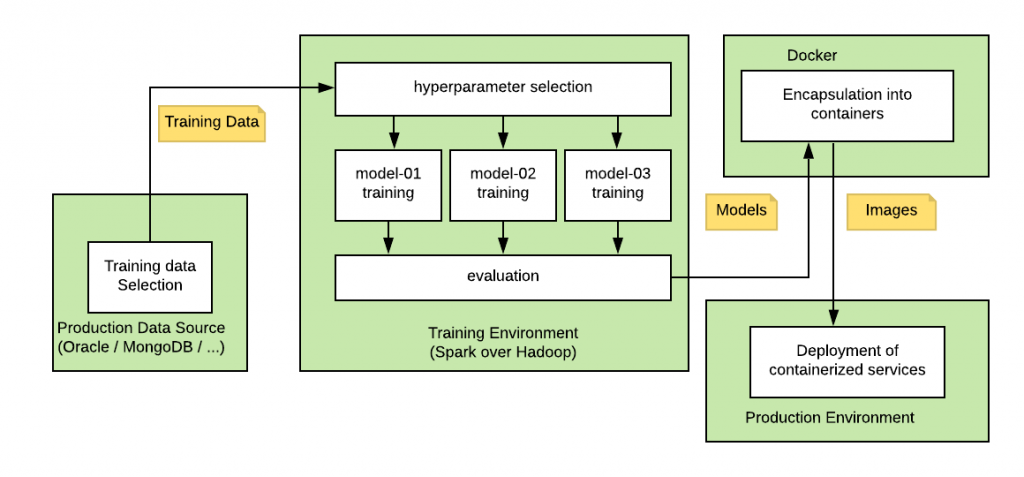
- The data warehouse (Oracle / MongoDB / filesystem) contains the historical documents selected for training phase.
- The training environment built on Apache Spark cluster is capable of training several kernels to identify the hyperparameter combination that yields model with optimal accuracy
- the kernels themselves are defined in SciKit-Learn or Keras, Spark ML Lib being an alternative.
- The trained models end up encapsulated in the form of a Docker container, providing them with either REST-type or streaming-type input/output interface
- In this form, the containerized models are deployed in production environment
At this point the production pipeline starts. A reference diagram is shown below. The workflow is as follows:
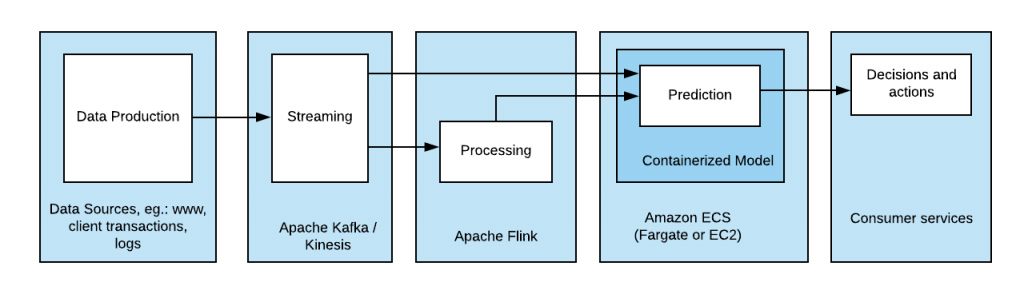
- After some initial preprocessing, the incoming document end up as a new record in a Kafka topic
- Apache Flink is used for additional processing and data cleansing or reorganization, such as, for instance, separation of scanned documents and text correspondence into two separate topics (image recognition might require a specialized classifier)
- The containerized model runs the classification.
- The containerized model resides inside Amazon ECS (Fargate or EC2) for better scalability, deployment and lifecycle management
- The classifier outcome is consumed by other services. This communication might also be streamed using Kafka
Those two pipelines taken together define a simple end-to-end scenario allowing to deploy a ML model in production. This reference architecture can be extended and modified in many ways. For instance, the streaming topology can be made significantly more complex, or Amazon Kinesis might be used in place of Kafka.
Understanding the workflow conceptually is not that difficult. The main problem lies in the significant number of technologies that need to be orchestrated together, each of them with their own dependencies, config options, limitations and gotchas. During the workshops we are demystifying the overall picture and building these end-to-end pipelines.
Note that the production phase pipeline is not specific to Machine Learning. In fact, the containerized model (visible in the Amazon ECS box in the diagram) can be replaced by any service. In the workshop Big Data for Managers, we focus on building this pipeline without particular focus on data science. The goal of the workshop is to understand how Kafka, Docker, REST and Amazon AWS cloud environment play together in one orchestrated workflow.
In the workshop Data Engineering for Data Scientists, we build both pipelines, with the focus on the needs specific to Data Science and Machine Learning models.