
Two people will interpret the same data in different ways. It is a norm, rather than exception. Due to the human factor (personal experience, emotions, deficiencies of human brain and tendency to fall for logical fallacies) understanding of the data is not an easy topic.
Data literacy (enhancing the abilities to interpret the data) should be taught as part of school curriculum. Below are six examples from my Data Analysis projects when the data interpretation led to significant difficulties even by domain experts and specialists. I also explain how we addressed the problem — either by better visualization, or by additional interpretation methods and statistical tools that led to remove the noise.
Understanding the data (data literacy)
- The phantom I followed: how the human brain misinterprets the data (techniques discussed: chi-square, Cramer’s V, Pearson, Spearman, scatter plot, apophenia)
- Data Puzzle: another example how even relatively simple visualization was misinterpreted by most people (positive correlation, right-skewness, log-normal distributions)
- The Truth Behind a Histogram Dent: a detective story on how a tiny feature in the histogram led to big discovery (bimodality, Spearman, Pearson, and Chi2 correlations)
- Mistaken by factor of 100,000: why lognormal data must be visualized with logarithmic scale
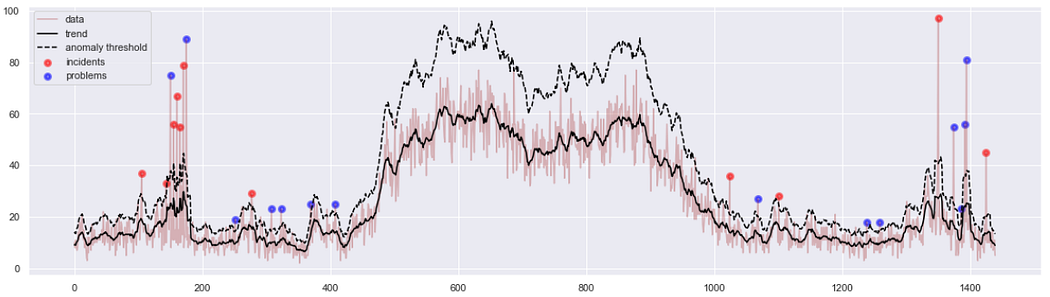
- How to tell anomalies in data drift: what constitutes a data anomaly and how to visualize it (EDA, outliers, IQR, histogram spikes)
- A picture worth 1,000 words: elimination of random noise from the time-series histogram (Exponentially-Weighted Moving Average (EMA), simple moving average (SMA), Boxcar Filter)
Data Literacy: Six examples of bad data interpretation